mirror of
https://github.com/tencentmusic/supersonic.git
synced 2025-12-11 03:58:14 +00:00
2.1 KiB
2.1 KiB
text2sql功能相关配置
简介
text2sql的功能实现,高度依赖对LLM的应用。通过LLM生成SQL的过程中,利用小样本(few-shots-examples)通过思维链(chain-of-thoughts)的方式对LLM in-context-learning的能力进行引导,对于生成较为稳定且符合下游语法解析规则的SQL非常重要。用户可以根据自身需要,对样本池及样本的数量进行配置,使其更加符合自身业务特点。
配置方式
- 样本池的配置。
- supersonic/chat/core/src/main/python/llm/few_shot_example/sql_exampler.py为样本池配置文件。用户可以以已有的样本作为参考,配置更贴近自身业务需求的样本,用于更好的引导LLM生成SQL。
- 样本数量的配置。
- 在supersonic/chat/core/src/main/python/llm/run_config.py 中通过 TEXT2DSL_FEW_SHOTS_EXAMPLE_NUM 变量进行配置。
- 默认值为15,为项目在内部实践后较优的经验值。样本少太少,对导致LLM在生成SQL的过程中缺少引导和示范,生成的SQL会更不稳定;样本太多,会增加生成SQL需要的时间和LLM的token消耗(或超过LLM的token上限)。
-
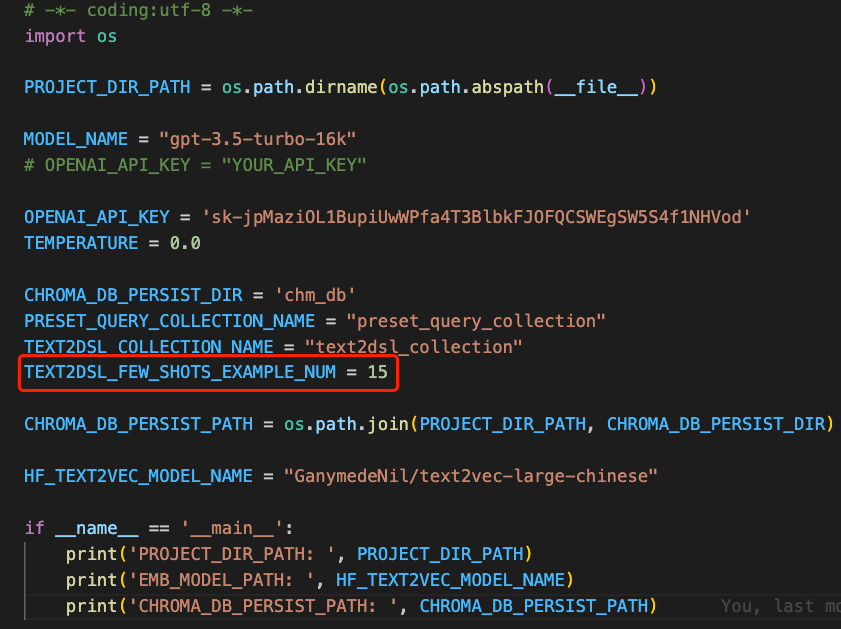
图1-1 样本数量的配置文件

- 运行中更新配置的脚本。
- 如果在启动项目后,用户需要对text2sql功能的相关配置进行调试,可以在修改相关配置文件后,通过脚本 supersonic/chat/core/src/main/python/bin/text2sql_resetting.sh 在项目运行中让配置生效。
FAQ
- 生成一个SQL需要消耗的的LLM token数量太多了,按照openAI对token的收费标准,生成一个SQL太贵了,可以少用一些token吗?
- 可以。 用户可以根据自身需求,如配置方式1.中所示,修改样本池中的样本,选用一些更加简短的样本。如配置方式2.中所示,减少使用的样本数量。
- 需要注意,样本和样本数量的选择对生成SQL的质量有很大的影响。过于激进的降低输入的token数量可能会降低生成SQL的质量。需要用户根据自身业务特点实测后进行平衡。