# 超音数(SuperSonic)
**超音数是一个开箱即用且易于扩展的数据问答对话框架**。通过超音数的问答对话界面,用户能够使用自然语言查询数据,系统会选择合适的可视化图表呈现结果。超音数不需要修改或复制数据,只需要在物理数据模型之上构建逻辑语义模型(指标/维度/实体的定义,以及他们的业务含义、相互间关系等),即可开启数据问答体验。与此同时,超音数被设计为可插拔式的框架,允许以插件形式来扩展新功能,或者将核心组件与其他系统集成。
 ## 项目动机
大型语言模型(LLMs)如ChatGPT的出现正在重塑信息检索的方式。在数据分析领域,学术界和工业界主要关注利用深度学习模型将自然语言查询转换为SQL查询。虽然一些工作显示出有前景的结果,但它们的可靠性还达不到生产可用的要求。
在我们看来,为了在实际场景发挥价值,有三个关键点:
1. 引入语义模型层,封装底层数据的上下文(关联、公式等),降低SQL生成的**复杂度**。
2. 通过一前一后的模式映射器和语义修正器,来缓解LLM常见的**幻觉**现象。
3. 设计启发式的规则,在一些特定场景提升语义解析的**效率**。
为了验证上述想法,我们开发了超音数项目,并将其应用在实际的内部产品中。与此同时,我们将超音数作为一个可扩展的框架开源,希望能够促进数据问答对话领域的进一步发展。
## 开箱即用的特性
- 内置对话界面以便*业务用户*输入数据查询。
- 内置图形界面以便*分析工程师*构建语义模型。
- 内置图形界面以便*系统管理员*管理第三方插件和对话助理。
- 支持文本输入的联想和查询问题的推荐。
- 支持多轮对话,根据语境自动切换上下文。
- 支持四级权限控制:主题域级、模型级、列级、行级。
## 易于扩展的组件
超音数的整体架构和主流程如下图所示:
## 项目动机
大型语言模型(LLMs)如ChatGPT的出现正在重塑信息检索的方式。在数据分析领域,学术界和工业界主要关注利用深度学习模型将自然语言查询转换为SQL查询。虽然一些工作显示出有前景的结果,但它们的可靠性还达不到生产可用的要求。
在我们看来,为了在实际场景发挥价值,有三个关键点:
1. 引入语义模型层,封装底层数据的上下文(关联、公式等),降低SQL生成的**复杂度**。
2. 通过一前一后的模式映射器和语义修正器,来缓解LLM常见的**幻觉**现象。
3. 设计启发式的规则,在一些特定场景提升语义解析的**效率**。
为了验证上述想法,我们开发了超音数项目,并将其应用在实际的内部产品中。与此同时,我们将超音数作为一个可扩展的框架开源,希望能够促进数据问答对话领域的进一步发展。
## 开箱即用的特性
- 内置对话界面以便*业务用户*输入数据查询。
- 内置图形界面以便*分析工程师*构建语义模型。
- 内置图形界面以便*系统管理员*管理第三方插件和对话助理。
- 支持文本输入的联想和查询问题的推荐。
- 支持多轮对话,根据语境自动切换上下文。
- 支持四级权限控制:主题域级、模型级、列级、行级。
## 易于扩展的组件
超音数的整体架构和主流程如下图所示:
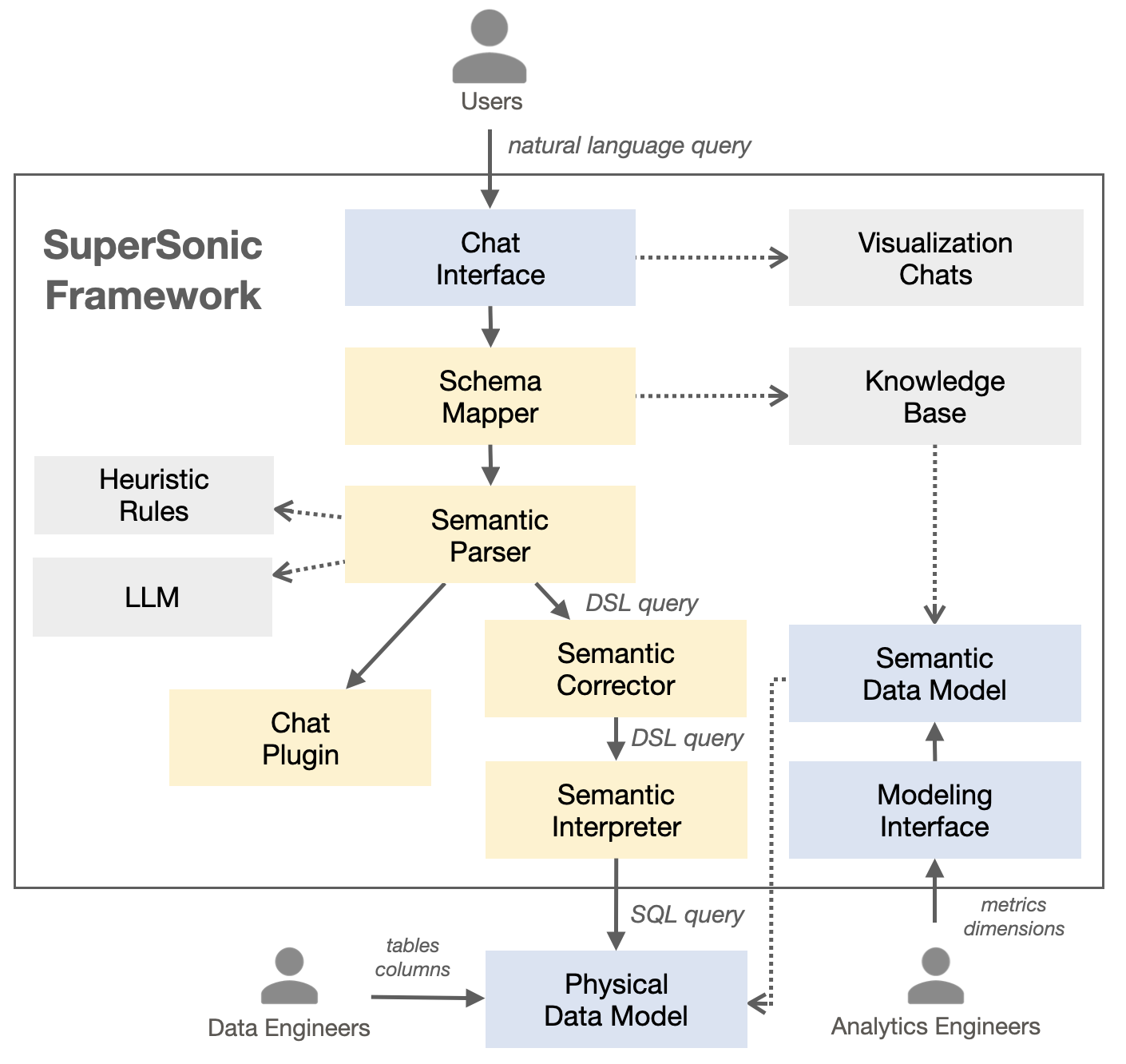 - **模型知识库(Knowledge Base):** 定期从语义模型中提取相关的模式信息,构建词典和索引,以便后续的模式映射。
- **模式映射器(Schema Mapper):** 将自然语言文本在知识库中进行匹配,为后续的语义解析提供相关信息。
- **语义解析器(Semantic Parser):** 理解用户查询并抽取语义信息,其由一组基于规则和基于模型的解析器组成,每个解析器可应对不同的特定场景。
- **语义修正器(Semantic Corrector):** 检查语义信息的合法性,对不合法的信息做修正和优化处理。
- **语义解释器(Semantic Interpreter):** 根据语义信息生成物理SQL执行查询。
- **问答插件(Chat Plugin):** 通过第三方工具扩展功能。给定所有配置的插件及其功能描述和示例问题,大语言模型将选择最合适的插件。
## 快速体验
超音数自带样例的语义模型和问答对话,只需以下三步即可快速体验:
- 从[release page](https://github.com/tencentmusic/supersonic/releases)下载预先构建好的发行包
- 运行 "bin/supersonic-daemon.sh"启动服务(一个Java进程和一个Python进程)
- 在浏览器访问http://localhost:9080 开启探索
## 如何构建和部署
请参考项目[wiki](https://github.com/tencentmusic/supersonic/wiki)。
## 微信联系方式
欢迎关注微信公众号:
- **模型知识库(Knowledge Base):** 定期从语义模型中提取相关的模式信息,构建词典和索引,以便后续的模式映射。
- **模式映射器(Schema Mapper):** 将自然语言文本在知识库中进行匹配,为后续的语义解析提供相关信息。
- **语义解析器(Semantic Parser):** 理解用户查询并抽取语义信息,其由一组基于规则和基于模型的解析器组成,每个解析器可应对不同的特定场景。
- **语义修正器(Semantic Corrector):** 检查语义信息的合法性,对不合法的信息做修正和优化处理。
- **语义解释器(Semantic Interpreter):** 根据语义信息生成物理SQL执行查询。
- **问答插件(Chat Plugin):** 通过第三方工具扩展功能。给定所有配置的插件及其功能描述和示例问题,大语言模型将选择最合适的插件。
## 快速体验
超音数自带样例的语义模型和问答对话,只需以下三步即可快速体验:
- 从[release page](https://github.com/tencentmusic/supersonic/releases)下载预先构建好的发行包
- 运行 "bin/supersonic-daemon.sh"启动服务(一个Java进程和一个Python进程)
- 在浏览器访问http://localhost:9080 开启探索
## 如何构建和部署
请参考项目[wiki](https://github.com/tencentmusic/supersonic/wiki)。
## 微信联系方式
欢迎关注微信公众号:
